New York State's plans to give $30 million to local newsrooms: Why it mattersBig publishers like Gannett and the New York Times aren’t eligible for the tax credits.Resume05:49Apr 25, 2024Is your teenager just moody? Or really struggling with mental health?The rate of kids dealing with serious mental health issues has been on the rise since the pandemic. But if parents want to help their kids, research suggests they should...Resume09:45Apr 25, 2024A cherrific discovery: Centuries-old bottles of cherries excavated from George Washington's homeTwo centuries-old bottles of preserved cherries were recently found in the basement of George Washington’s home at Mount Vernon.Resume03:40Apr 25, 2024Kevin Bacon visits high school where he starred in 'Footloose' 40 years agoThe Utah high school where "Footloose" was filmed invited Kevin Bacon to visit for their prom on the 40th anniversary of the film's release.Resume04:12Apr 25, 2024California's oldest water rights exist only on paper. A new project aims to change thatCollege students in California have begun scanning 2 million pages of water rights records on paper to make them more easily available in digital form to the public as part...Resume06:11Apr 25, 2024AdvertisementTrump claims he's immune from prosecution. Supreme Court hears arguments in the caseFormer President Donald Trump claims that he is immune from prosecution on charges that he plotted to overturn his loss in the 2020 election.Resume05:32Apr 25, 2024What's behind House Speaker Mike Johnson's big gamble on foreign aidHouse Speaker Mike Johnson has been moving a big foreign aid package through the House.Resume05:06Apr 25, 2024'Beyond dreams': An Oregon drumline celebrates successThe Kingsmen Thunder Drumline at Rex Putnam High School in Milwaukie, Oregon, just returned from their first appearance at the Percussion World Championships.Resume01:16Apr 25, 2024The demise of a West Virginia newspaperMissy Nester grew up in Welch and bought a paper in 2018 to save it. But she couldn't make the economics work and last year, shuttered the Welch News.Resume09:59Apr 25, 2024New airline rules make it easier to get refunds for delayed or canceled flightsTaking effect over the next two years, the new rules will require airlines to issue consumers automatic cash refunds within a few weeks.Resume03:39Apr 25, 2024Detroit debuts 'road of the future' with wireless electric vehicle chargingDetroit is testing a new way to charge electric vehicles that don’t require plugging in. Just park or drive your car on the right strip of road and watch the...Resume09:32Apr 25, 2024Supreme Court hears arguments in Trump immunity claimsThe Supreme Court is hearing arguments in former President Donald Trump's claims that he should be immune from prosecution on charges that he plotted to subvert his 2020 election loss.Resume06:27Apr 25, 2024Teachers can now carry concealed handguns in TennesseeTennessee lawmakers passed a bill allowing teachers to carry concealed handguns in schools despite heavy protests at the state capitol.Resume04:50Apr 25, 2024Arizona jury indicts Trump allies in 'fake elector' schemeA grand jury indicted former White House Chief of Staff Mark Meadows, Rudy Giuliani, John Eastman, and other allies of former President Donald Trump for their efforts involvement in a...Resume06:06Apr 25, 2024Shipbuilders harness the wind to clean up global shippingContainer ships use heavy fuel oil called bunker fuel. They’re more efficient than trains, trucks and planes. But bunker fuel is highly polluting, and container ships produce about 3% of...Resume09:40Apr 24, 2024UN official 'horrified' by mass grave discovery: The latest updates from GazaPalestinian officials say they exhumed 283 bodies.Resume05:35Apr 24, 2024Lachlan Cartwright recounts 'catch and kill' at the National EnquirerTrump is accused of falsifying business records to unlawfully influence the 2016 presidential election. At the center of the trial are payments that the National Enquirer made to keep damaging...Resume10:59Apr 24, 2024Pennsylvania primary: Takeaways and surprisesThe results could provide important insight into how November’s general election might unfold in the swing state.Resume05:51Apr 24, 2024California cracks down on groundwater usageCalifornia's state board that regulates water recently voted to impose fees for farmers using groundwater in one of the state's largest farming areas.Resume05:46Apr 24, 2024NHL playoffs underwayThe playoffs have already had several close games and plenty of upset victories as teams battle to reach the Stanley Cup final.Resume03:47Apr 24, 2024Next Page
New York State's plans to give $30 million to local newsrooms: Why it mattersBig publishers like Gannett and the New York Times aren’t eligible for the tax credits.Resume05:49Apr 25, 2024
Is your teenager just moody? Or really struggling with mental health?The rate of kids dealing with serious mental health issues has been on the rise since the pandemic. But if parents want to help their kids, research suggests they should...Resume09:45Apr 25, 2024
A cherrific discovery: Centuries-old bottles of cherries excavated from George Washington's homeTwo centuries-old bottles of preserved cherries were recently found in the basement of George Washington’s home at Mount Vernon.Resume03:40Apr 25, 2024
Kevin Bacon visits high school where he starred in 'Footloose' 40 years agoThe Utah high school where "Footloose" was filmed invited Kevin Bacon to visit for their prom on the 40th anniversary of the film's release.Resume04:12Apr 25, 2024
California's oldest water rights exist only on paper. A new project aims to change thatCollege students in California have begun scanning 2 million pages of water rights records on paper to make them more easily available in digital form to the public as part...Resume06:11Apr 25, 2024
Trump claims he's immune from prosecution. Supreme Court hears arguments in the caseFormer President Donald Trump claims that he is immune from prosecution on charges that he plotted to overturn his loss in the 2020 election.Resume05:32Apr 25, 2024
What's behind House Speaker Mike Johnson's big gamble on foreign aidHouse Speaker Mike Johnson has been moving a big foreign aid package through the House.Resume05:06Apr 25, 2024
'Beyond dreams': An Oregon drumline celebrates successThe Kingsmen Thunder Drumline at Rex Putnam High School in Milwaukie, Oregon, just returned from their first appearance at the Percussion World Championships.Resume01:16Apr 25, 2024
The demise of a West Virginia newspaperMissy Nester grew up in Welch and bought a paper in 2018 to save it. But she couldn't make the economics work and last year, shuttered the Welch News.Resume09:59Apr 25, 2024
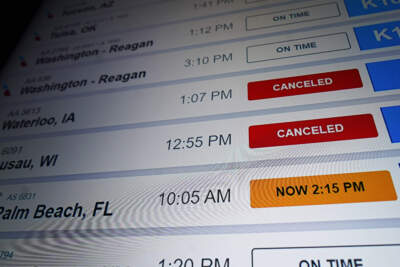
New airline rules make it easier to get refunds for delayed or canceled flightsTaking effect over the next two years, the new rules will require airlines to issue consumers automatic cash refunds within a few weeks.Resume03:39Apr 25, 2024
Detroit debuts 'road of the future' with wireless electric vehicle chargingDetroit is testing a new way to charge electric vehicles that don’t require plugging in. Just park or drive your car on the right strip of road and watch the...Resume09:32Apr 25, 2024
Supreme Court hears arguments in Trump immunity claimsThe Supreme Court is hearing arguments in former President Donald Trump's claims that he should be immune from prosecution on charges that he plotted to subvert his 2020 election loss.Resume06:27Apr 25, 2024
Teachers can now carry concealed handguns in TennesseeTennessee lawmakers passed a bill allowing teachers to carry concealed handguns in schools despite heavy protests at the state capitol.Resume04:50Apr 25, 2024
Arizona jury indicts Trump allies in 'fake elector' schemeA grand jury indicted former White House Chief of Staff Mark Meadows, Rudy Giuliani, John Eastman, and other allies of former President Donald Trump for their efforts involvement in a...Resume06:06Apr 25, 2024
Shipbuilders harness the wind to clean up global shippingContainer ships use heavy fuel oil called bunker fuel. They’re more efficient than trains, trucks and planes. But bunker fuel is highly polluting, and container ships produce about 3% of...Resume09:40Apr 24, 2024
UN official 'horrified' by mass grave discovery: The latest updates from GazaPalestinian officials say they exhumed 283 bodies.Resume05:35Apr 24, 2024
Lachlan Cartwright recounts 'catch and kill' at the National EnquirerTrump is accused of falsifying business records to unlawfully influence the 2016 presidential election. At the center of the trial are payments that the National Enquirer made to keep damaging...Resume10:59Apr 24, 2024
Pennsylvania primary: Takeaways and surprisesThe results could provide important insight into how November’s general election might unfold in the swing state.Resume05:51Apr 24, 2024
California cracks down on groundwater usageCalifornia's state board that regulates water recently voted to impose fees for farmers using groundwater in one of the state's largest farming areas.Resume05:46Apr 24, 2024
NHL playoffs underwayThe playoffs have already had several close games and plenty of upset victories as teams battle to reach the Stanley Cup final.Resume03:47Apr 24, 2024